
前回はC言語の標準規格の話と glibc の実装を取り上げたが、今回は Visual C++ のランタイムライブラリである MSVCRT を取り上げる。MSVCRT は Visual C++ でコンパイルしたプログラムだけではなく、 MinGW でも使われる。
目次:
- MSVCRT におけるワイド文字入出力
- 例1:ワイド文字出力
- 例2:fopen への ccs 指定
- 例2b:バイナリモードと ccs 指定
- 例3:ccs 指定と fwrite
- 例4:ファイルからの読み込み
- 例5:_setmode 関数
MSVCRT におけるワイド文字入出力
text mode / binary mode
「ナントカ stream」よりは、もっぱら、 text mode / binary mode という語の方が使われているようだ。ご存知の通り、 text mode の場合は CRLF と LF の変換を行う。
Unicode mode
MSVCRT には orientation の概念はない。fwide 関数も実装されていない。【MSDN: fwide 関数】
ただし、 wide-oriented stream に似た概念として、 “Unicode mode” というモードがある。ストリームは text mode / binary mode / Unicode mode の3状態のいずれかである。Unicode mode は text mode と同様に、改行コードの変換を行う。
Unicode mode はさらに UNICODE モード (_O_WTEXT)、UTF-8 モード (_O_U8TEXT)、UTF-16LE モード (_O_U16TEXT) の3つに細分できる。これらはファイルに読み書きする際のエンコーディングが若干変わる程度で、プログラムから入出力関数を呼ぶ上ではそんなに違いがない。(UNICODE モードと UTF-16LE モードは、ぶっちゃけ何が違うのかよくわからないのだが…。)
標準 C では fwide 関数によって orientation を取得できたが、 MSVCRT で現在の mode を取得するには _setmode の戻り値を使うしかなさそうである。
ストリームの各モードと I/O 関数の関係
text mode なストリームに対して wide character I/O function を呼び出した場合は、 mbtowc/wctomb による変換を介して動作する。mbtowc/wctomb のマルチバイト文字の文字コードは、ロケール (LC_CTYPE) に依存する。【MSDN: Unicode Stream I/O in Text and Binary Modes】
binary mode なストリームに対して wide character I/O function を呼んだ場合は、バイト列を UTF-16LE (wchar_t の配列そのまま)として解釈する。【MSDN: Unicode Stream I/O in Text and Binary Modes】
Unicode mode に対する byte I/O function の呼び出しは、エラーとなる。例外として、 fread 関数と fwrite 関数は引数を UTF-16LE と解釈して動作する。fread, fwrite 関数を使った場合でも、改行コードの変換はしっかりと行われる。(→例3, 例4)(fread, fwrite の他に Unicode mode でも使える byte I/O function があるかは未調査)【MSDN: fwrite 関数】
C の規格にある orientation の考えでいくと、wide character I/O function を Unicode mode 専用にして、 binary mode や text mode なストリームに対する呼び出しを一律で禁止してしまっても良さそうに思える。そうなっていないのは、おそらく歴史的経緯によるものだろう。(Unicode mode が導入されたのはバージョン 8.0 (2005) だが、ワイド文字版の入出力関数はそれ以前からあった)
以上の挙動を図にまとめると、次のようになる:
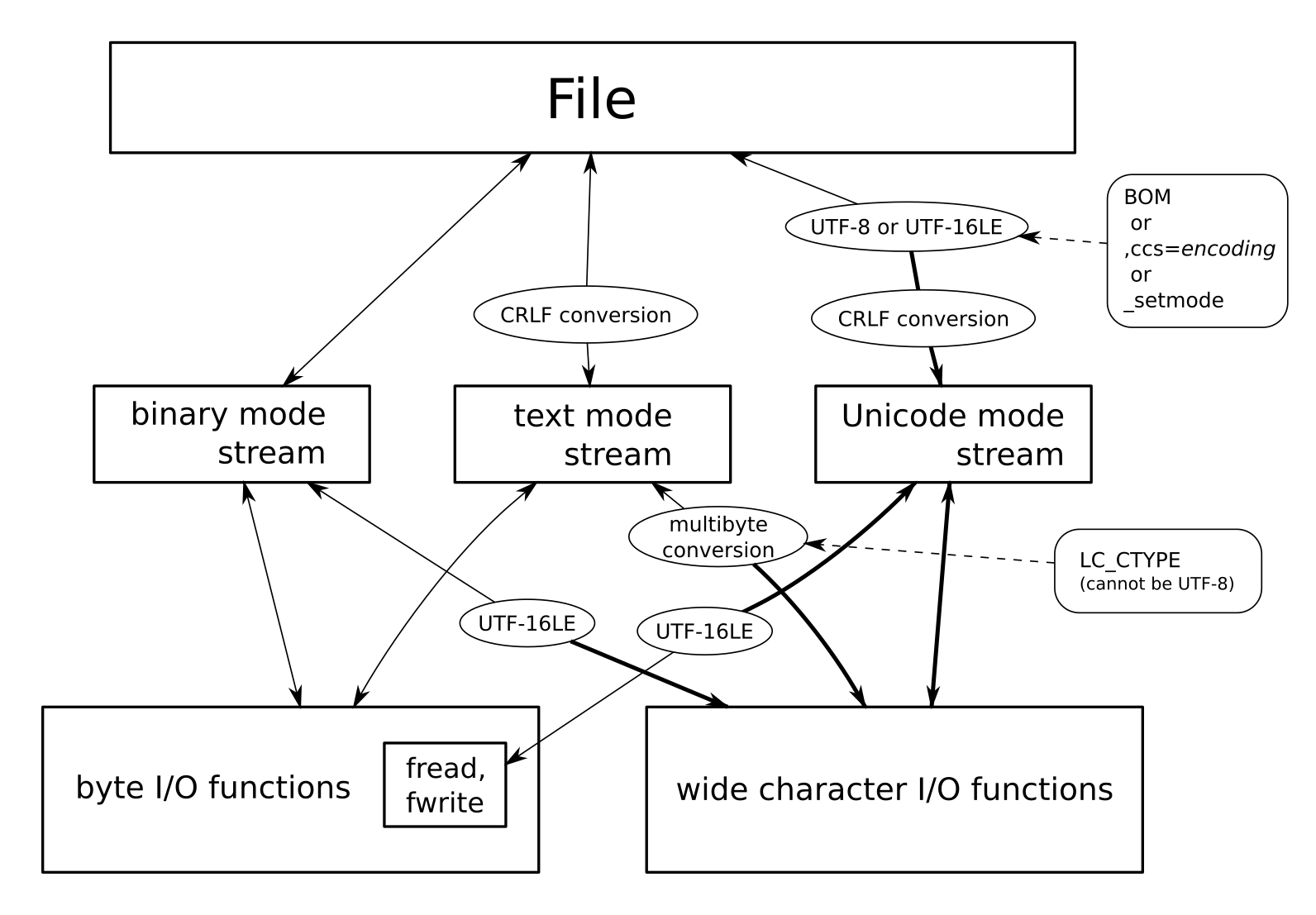 太線はワイド文字 (Unicode) でやり取りされる部分である。
太線はワイド文字 (Unicode) でやり取りされる部分である。
fopen に ccs を指定した場合
MSVCRT の fopen の mode 引数には、 "w,ccs=UTF-8" というように、 Unicode 系のエンコードの一部 (“UNICODE”, “UTF-8”, “UTF-16LE”) を指定できる。ここで指定できる “UNICODE” と “UTF-16LE” は同義である。【MSDN: fopen — Unicode Support】
この仕様は Visual C++ 8.0 (2005) で初登場したもので、比較的最近(※)である。元ネタは glibc の仕様だと思われる。(ただし、設定できる文字コードの種類と、 BOM の扱いが異なる)【MSDN: fopen 関数 (VC7.1)】【MSDN: fopen 関数 (VC8.0)】
※比較的最近:筆者が初めて使い込んだ Visual C++ のバージョンは 7.1 (2003) なので、それと比較すると新しい、程度の意味。
ccs を指定すると、ストリームは開いた時点で Unicode mode となる。
ファイルを読み取る際は、ファイルに UTF-16LE または UTF-8 の BOM が付いていればそれに従い、そうでない場合は引数で指定されたもの(UTF-16LE または UTF-8)を使う。書き出しの際には常に BOM がつく。なお、 UTF-16BE の BOM は認識されない。
なお、 fopen と _wfopen は、引数の型が違う (const char * vs const wchar_t *) だけであり、ストリームのモードには影響しない。
_setmode 関数
_setmode 関数を使うと、既に開いたストリームに対して binary mode (_O_BINARY) / text mode (_O_TEXT) / Unicode mode (_O_WTEXT, _O_U16TEXT, _O_U8TEXT) を設定できる。(→例5)【MSDN: _setmode 関数】
_setmode で Unicode mode を指定できるようになったのは Visual C++ 9.0 (2008) 以降のようである。(少なくとも、ドキュメント化されている限りでは)【MSDN: _setmode 関数 (VC8.0)】【MSDN: _setmode 関数 (VC9.0)】
ファイルを開く際には fopen 関数の ccs 指定が使えるので、もっぱら標準入出力 (stdin, stdout, stderr) に関して有用な関数だと思われる。
参考:ロケールについて
“C” ロケールの場合は、8ビットに収まる値はそのままバイト値になり、そうでない値(U+0100 以上の値)は変換に失敗する。プログラムの起動時はロケールが “C” となっているので、ワイド文字出力関数で非8ビットの値は出力できない。
setlocale に空文字列を渡す、つまり setlocale(LC_ALL, "") を実行すれば、システムデフォルトのロケールが使われる。ただし、 POSIX とは違って、環境変数には影響されない(…はず)。
setlocale に空でない文字列を与え、システムの設定とは異なるロケールを使うことも可能である。
残念ながら、MSVCRT の setlocale 系の関数には、UTF-8 のような、1文字が3バイト以上となる文字コードは指定できない。(これが嫌だったら Windows を窓から投げ捨てるか、自力で CRT を再実装するべし)【MSDN: setlocale 関数】
ここでの実行例では Unix-like なターミナル (MSYS2) で、 Visual C++ のコンパイラー (cl.exe) を使ってコンパイルしているが、仮に MinGW を使ったとしても、概ね同じ結果になるはずである。
例1:ワイド文字出力
前回と同じ test1.c を使う。
“C” ロケールの場合
$ cl -nologo test1.c test1.c $ ./test1 LC_CTYPE = C LC_ALL = C orientation is not set. [0] fputws successful. [0] fputws failed. [-1] fputws failed. [-1] orientation is byte. [-1] fputs successful. [0] $ hexdump -C out.txt 00000000 43 61 66 e9 20 61 75 20 6c 61 69 74 0d 0a 43 61 |Caf. au lait..Ca| 00000010 66 e9 20 61 75 20 6c 61 69 74 0d 0a |f. au lait..| 0000001c
MSVCRT には orientation の概念がないので、 fputws を呼んだ後でも fputs の呼び出しが成功する。(fwide 関数は第2引数をそのまま返すようになっている)
“é” (U+00E9) は値が8ビットに収まるので、 0xe9 として書き込まれた。一方、 U+03B6 や U+3042 を書き込もうとすると、バイト値への変換に失敗して fputws の呼び出しが失敗する。この挙動は BSD libc と似ている。
言うまでもないが、テキストモードなので、改行コード \n は 0x0d 0x0a (CRLF) に変換されて書き込まれている。
システムデフォルトのロケールの場合(”Japanese_Japan” ロケールの場合)
setlocale に空文字列を与えると、システムデフォルトのロケールが使用される。以下は日本語環境で実行した例で、コードページが CP932 となっている。非日本語環境で実行して同じ結果を得るには、 “Japanese_Japan” ロケールを指定すれば良い。
$ ./test1 "" LC_CTYPE = Japanese_Japan.932 LC_ALL = LC_COLLATE=C;LC_CTYPE=Japanese_Japan.932;LC_MONETARY=C;LC_NUMERIC=C;LC_TIME=C orientation is not set. [0] fputws successful. [0] fputws successful. [0] fputws successful. [0] orientation is byte. [-1] fputs successful. [0] $ hexdump -C out.txt 00000000 43 61 66 65 20 61 75 20 6c 61 69 74 0d 0a 83 c4 |Cafe au lait....| 00000010 0d 0a 82 a0 0d 0a 43 61 66 e9 20 61 75 20 6c 61 |......Caf. au la| 00000020 69 74 0d 0a |it..| 00000024
fputws に渡した “é” は、アクサンのつかない “e” に変換されて書き込まれている。
“ζ”, “あ” は Shift_JIS にもあるので、 Shift_JIS として書き込まれている。
“French_France” ロケールの場合
$ ./test1 "French_France" LC_CTYPE = French_France.1252 LC_ALL = LC_COLLATE=C;LC_CTYPE=French_France.1252;LC_MONETARY=C;LC_NUMERIC=C;LC_TIME=C orientation is not set. [0] fputws successful. [0] fputws failed. [-1] fputws failed. [-1] orientation is byte. [-1] fputs successful. [0] $ hexdump -C out.txt 00000000 43 61 66 e9 20 61 75 20 6c 61 69 74 0d 0a 43 61 |Caf. au lait..Ca| 00000010 66 e9 20 61 75 20 6c 61 69 74 0d 0a |f. au lait..| 0000001c
“é” が 0xe9 として書き込まれていることから、文字コードとしては ISO 8859-1 が使われていると思われる。
ISO 8859-1 にない文字を書き込もうとすると、fputws の呼び出しが失敗している。
“Greek_Greece” ロケールの場合
$ ./test1 "Greek_Greece" LC_CTYPE = Greek_Greece.1253 LC_ALL = LC_COLLATE=C;LC_CTYPE=Greek_Greece.1253;LC_MONETARY=C;LC_NUMERIC=C;LC_TIME=C orientation is not set. [0] fputws successful. [0] fputws successful. [0] fputws failed. [-1] orientation is byte. [-1] fputs successful. [0] $ hexdump -C out.txt 00000000 43 61 66 65 20 61 75 20 6c 61 69 74 0d 0a e6 0d |Cafe au lait....| 00000010 0a 43 61 66 e9 20 61 75 20 6c 61 69 74 0d 0a |.Caf. au lait..| 0000001f
“é” がアクサンのつかない “e” に化けている。
“ζ” は ISO 8859-7 での値である 0xe6 で書き込まれている。
日本語の文字を出力しようとしたら fputws の呼び出しが失敗している。
UTF-8 は…?
$ ./test1 "ja-JP.UTF-8" LC_CTYPE = C LC_ALL = C orientation is not set. [0] fputws successful. [0] fputws failed. [-1] fputws failed. [-1] orientation is byte. [-1] fputs successful. [0] $ ./test1 "ja-JP.65001" LC_CTYPE = C LC_ALL = C orientation is not set. [0] fputws successful. [0] fputws failed. [-1] fputws failed. [-1] orientation is byte. [-1] fputs successful. [0]
すでに書いたように、MSVCRT では setlocale で UTF-8 を指定することはできない。setlocale の呼び出し後も、ロケールは “C” のままとなった。
例2:fopen への ccs 指定
前回と同じ test2.c を使う。
$ cl -nologo test2.c test2.c $ ./test2 LC_CTYPE = C LC_ALL = C orientation is not set. [0] fputws successful. [0] fputws successful. [0] fputws successful. [0] orientation is not set. [0] invalid parameter handler: expression=(null), function=(null), file=(null), line=0 fputs failed. [-1] $ hexdump -C out.txt 00000000 ef bb bf 43 61 66 c3 a9 20 61 75 20 6c 61 69 74 |...Caf.. au lait| 00000010 0d 0a ce b6 0d 0a e3 81 82 0d 0a |...........| 0000001b
fputs の呼び出しが失敗しているのがわかる。(invalid parameter handler が呼ばれる。デフォルトの invalid parameter handler はプログラムを abort し、 fputs へ制御を返さない。)
書き出されたファイルは、 BOM 付きの UTF-8 エンコードとなっている。改行は CRLF である。
他のロケールを設定しても同じ結果となるため、省略する。
読者への演習:fopen の第2引数を "w, ccs=UTF-8" (カンマと “ccs” との間に空白を入れる)に変えても影響がない(出力が UTF-8 のままである)ことを確かめよ。
読者への演習:fopen の第2引数を "w,ccs=UNICODE" または "w,ccs=UTF-16LE" とした場合に、書き出されたファイルが BOM 付き UTF-16LE となることを確かめよ。
例2b:バイナリモードと ccs 指定
前回と同じ test2b.c を使う。
$ cl -nologo test2b.c test2b.c $ ./test2b LC_CTYPE = C LC_ALL = C orientation is not set. [0] fputws successful. [0] fputws successful. [0] fputws successful. [0] orientation is not set. [0] fputs successful. [0] $ hexdump -C out.txt 00000000 43 00 61 00 66 00 e9 00 20 00 61 00 75 00 20 00 |C.a.f... .a.u. .| 00000010 6c 00 61 00 69 00 74 00 0a 00 b6 03 0a 00 42 30 |l.a.i.t.......B0| 00000020 0a 00 43 61 66 e9 20 61 75 20 6c 61 69 74 0a |..Caf. au lait.| 0000002f
fopen の第2引数に 'b' を含めた場合、 ccs 指定は無視される。(つまり、 binary mode と Unicode mode は両立しない)
binary mode のストリームに対してワイド文字版の出力関数 (fputws) を呼ぶと、ワイド文字列の中身がそのまま(UTF-16LE として)吐き出される。その後に呼んだ fputs はいつも通りである。
言うまでもないが、改行コードの変換は行われない。
例3:ccs 指定と fwrite
前回と同じ test3.c を使う。
$ cl -nologo test3.c test3.c $ ./test3 fwrite successful. [13] $ hexdump -C out.txt 00000000 ef bb bf 43 61 66 c3 a9 20 61 75 20 6c 61 69 74 |...Caf.. au lait| 00000010 0d 0a |..| 00000012
MSVCRT の場合は、Unicode mode なストリームに対して fwrite を呼んだ場合、引数は wchar_t の配列として解釈される。この例では UTF-8 として書き込まれている。【MSDN: fwrite 関数】
例4:ファイルからの読み込み
前回と同じ test4.c を使う。
$ cl -nologo ../test4.c test4.c $ ./test4 LC_CTYPE = C LC_ALL = C Read from UTF-8-encoded file (with ccs=UTF-8): 00e9 03b6 3042 d83c df76 000a Read from UTF-8-encoded file (with ccs=UNICODE): 00c3 00a9 00ce 00b6 00e3 0081 0082 00f0 009f fopen(inout-u8.txt, r,ccs=UTF-16) failed. Read from UTF-8-encoded file (with ccs=UTF-16LE): a9c3 b6ce 81e3 f082 8d9f 0db6 Read from UTF-8 (with BOM)-encoded file (with ccs=UTF-8): 00e9 03b6 3042 d83c df76 000a Read from UTF-8 (with BOM)-encoded file (with ccs=UNICODE): 00e9 03b6 3042 d83c df76 000a fopen(inout-u8bom.txt, r,ccs=UTF-16) failed. Read from UTF-8 (with BOM)-encoded file (with ccs=UTF-16LE): 00e9 03b6 3042 d83c df76 000a Read from UTF-16LE (with BOM)-encoded file (with ccs=UTF-8): 00e9 03b6 3042 d83c df76 000a Read from UTF-16LE (with BOM)-encoded file (with ccs=UNICODE): 00e9 03b6 3042 d83c df76 000a fopen(inout-u16le.txt, r,ccs=UTF-16) failed. Read from UTF-16LE (with BOM)-encoded file (with ccs=UTF-16LE): 00e9 03b6 3042 d83c df76 000a fopen(inout-u16be.txt, r,ccs=UTF-8) failed. fopen(inout-u16be.txt, r,ccs=UNICODE) failed. fopen(inout-u16be.txt, r,ccs=UTF-16) failed. fopen(inout-u16be.txt, r,ccs=UTF-16LE) failed. Read from UTF-8-encoded file with fread: 00e9 03b6 3042 d83c df76 000a Read from UTF-8-encoded file with fread: e9 00 b6 03 42 30 3c d8 76 df 0a 00
ccs の文字コードとして指定できるのは、 “UTF-8”, “UNICODE”, “UTF-16LE” だけである。”UTF-16″ や “UTF-16BE” は指定できない。
いずれの場合も、 UTF-8, UTF-16 LE の BOM があった場合は解釈されてそのエンコーディングで読まれる。一方、 UTF-16 BE の BOM は認識されず、 fopen の時点で失敗する。
“UNICODE” の場合、サロゲートペアはそのまま素通りする(読み取った結果も UTF-16 なので)。サロゲートペアが正しい組み合わせになっているかという検証はされない。
Unicode mode のストリームに対して fread を呼んだ場合、ファイルから読み取られた Unicode 文字列が UTF-16LE でバイト列に変換される。
例5:_setmode 関数
すでに開かれたストリームのモードを _setmode によって変更してみる。
実行結果:
$ cl -nologo test-setmode.c test-setmode.c $ ./test-setmode LC_CTYPE = C LC_ALL = C fputws successful. [0] fputws successful. [0] fputs successful. [0] fputs successful. [0] $ hexdump -C out.txt 00000000 43 61 66 c3 a9 20 61 75 20 6c 61 69 74 0d 0a 43 |Caf.. au lait..C| 00000010 00 61 00 66 00 e9 00 20 00 61 00 75 00 20 00 6c |.a.f... .a.u. .l| 00000020 00 61 00 69 00 74 00 0d 00 0a 00 43 61 66 e9 20 |.a.i.t.....Caf. | 00000030 61 75 20 6c 61 69 74 0d 0a 43 61 66 e9 20 61 75 |au lait..Caf. au| 00000040 20 6c 61 69 74 0a | lait.| 00000046
fopen の直後に _O_U8TEXT を設定しているが、 BOM は書き込まれない。
_O_U16TEXT を指定した場合、ファイルの途中から UTF-16LE となっている。
_O_BINARY, _O_TEXT, _O_WTEXT, _O_U16TEXT, _O_U8TEXT はそれぞれ異なる bit が立っていて、bitwise or を取れそうであるが、例えば _O_BINARY | _O_U8TEXT を指定すると _setmode は失敗する。(つまり、 binary mode と Unicode mode は両立しない)
結論
MSVCRT はクソだし、ワイド文字という概念もクソである。
ピンバック: C言語のワイド文字入出力 | 雑記帳
ピンバック: C言語のワイド文字入出力 — Windows Console 編 | 雑記帳
ピンバック: TeX Live 2018でWindows上のTeXworksが日本語を含むファイル名を扱えない話 | 雑記帳