
C言語にはワイド文字で入出力を行う関数が用意されている。
※ワイド文字:C言語のワイド文字 (wchar_t) とは、不憫な子である。Windows だと Unicode のコードポイント1個すら表せない16ビットだったり、Unix だとそもそも使われている気配があまりなかったり(もっぱら UTF-8 か UTF-16 が使われている印象がある)する。2010年代の後半にもなってワイド文字なんぞを真面目に扱うブログというのは時代錯誤も甚だしい。
ワイド文字で入出力と言っても、対象がファイルの場合は最終的にはバイト列を読み書きしているわけで、どこかの段階でバイト列とワイド文字列との変換が行われているはずである。この変換方法はどうやって決まっているのか。あるいは、ワイド文字の入出力関数とバイト列 (char) の入出力関数を混在させるとどうなるのか。
また、Visual C++ や glibc の場合は fopen の第2引数に ,ccs=UTF-8 みたいな文字列を設定できるという謎の仕様がある。これを指定した場合は何が UTF-8 になるのか。
こういった細かい仕様は、ワイド文字自体がオワコンなこともあり、あまり知られていないように思う。少なくとも筆者は知らなかった。というわけで、
- ワイド文字による入出力について、C言語の規格ではどう定められているか
- Visual C++ のランタイムライブラリ (MSVCRT) ではどう実装されているか
- Linux 等で使われている glibc ではどう実装されているか
- macOS 等で使われている BSD libc ではどう実装されているか
の4点について調べた。(ただし、 MSVCRT については別の記事に分割する)
目次:
- C言語の規格
- glibc における実装
- BSD libc における実装
- (別記事)MSVCRT における実装
- 例1:ワイド文字出力
- 例2:fopen への ccs 指定
- 例2b:バイナリモードと ccs 指定
- (別記事)MSVCRT での実行結果
- 例3:ccs 指定と fwrite
- 例4:ファイルからの読み込み
C言語の規格
C言語の規格では、ワイド文字列の入出力についてどのように定められているだろうか。(C11 の最終ドラフト N1570 を参照した)
ワイド文字
wchar_t 型は、現在のロケールにおける全ての文字を表せる。【3.7.3 節】
wchar_t が Unicode な場合は、 __STDC_ISO_10646__ マクロが定義される。【6.10.8.2 節】
wchar_t が32ビットな環境であっても、入っている値が Unicode ではない場合がある。
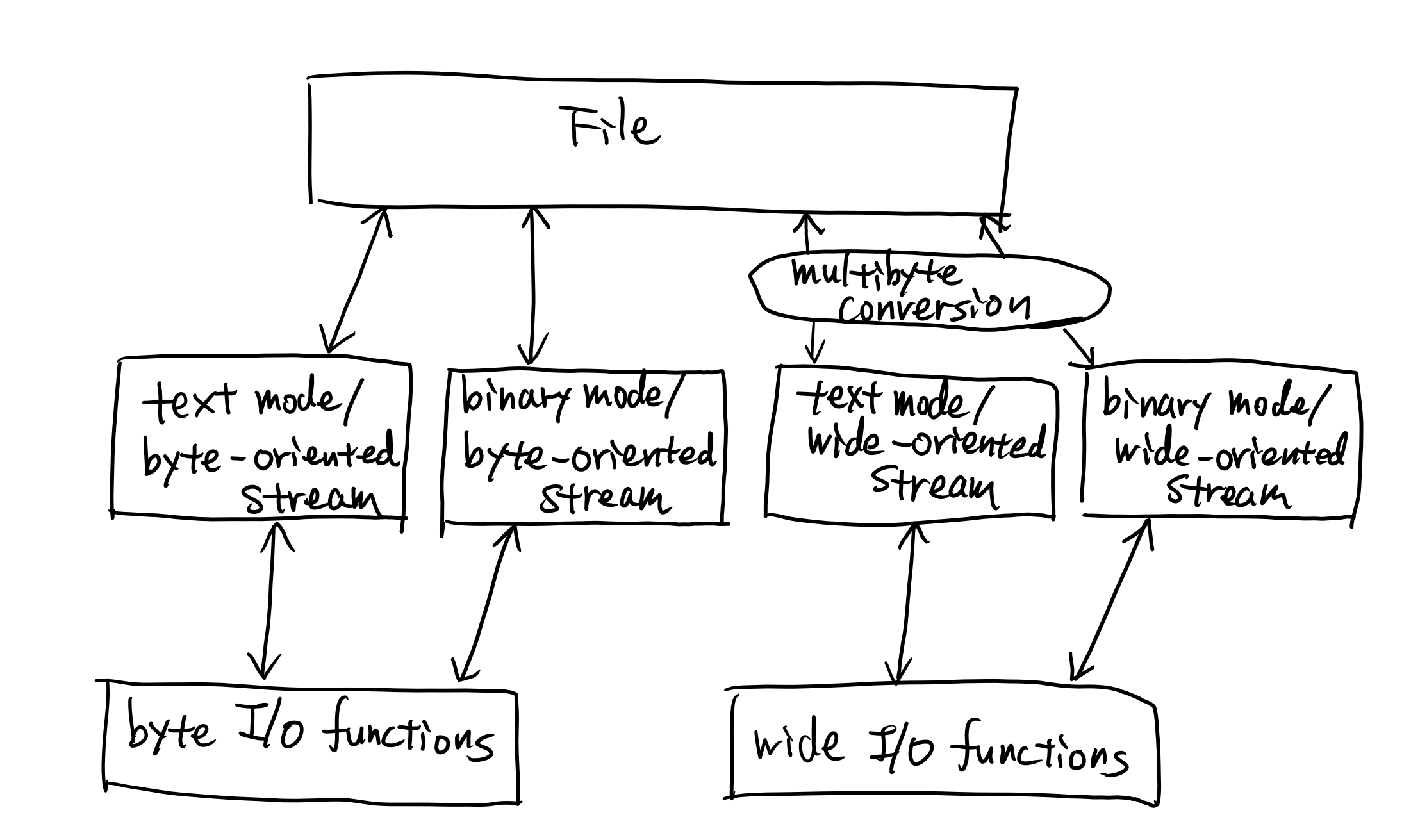
byte I/O function と wide character I/O function
規格の 7.21.1 節で定義されている。
byte input/output function: char を読み書きする入出力関数。(例:fputs)
wide character input/output functions: ワイド文字 (wchar_t) を読み書きする入出力関数。(例:fputws)
text stream / binary stream
わざわざ説明する必要はないだろう。【7.21.2 節】
byte-oriented stream / wide-oriented stream (orientation)
各ストリームは orientation と呼ばれる状態を持つ。これは、未設定, byte-oriented, wide-oriented の3つのうち、いずれかである。【7.21.2 節】
fopen した直後のストリームは orientation が定まっていない。最初に読んだ I/O 関数の種類 (byte I/O function または wide character I/O function) によって orientation が決まる。
fwide 関数によってストリームの orientation を取得、未設定の場合は設定することができる。(既にストリームの orientation が決まっていた場合に再設定できるかどうかは実装依存なように読める)
byte-oriented stream に対して wide character I/O function を呼び出してはいけない。逆も同様で、 wide-oriented stream に対して byte I/O function を呼び出してはいけない。
(こういうのはストリームの型で区別すべきだろうと思うが、文字入出力以外のストリームに関する関数まで2倍に増やすことはしたくなかったのだろうか)
ファイルを読み書きする場合、wide character I/O function は、ストリームからマルチバイト文字列を読み書きして、mbrtowc/wcrtomb 関数でワイド文字列に変換する。【7.21.3 節】
byte I/O function がワイド文字を扱う場合(fprintf で %ls 指定子を使う場合が該当するだろうか)も、 mbrtowc/wcrtomb 関数を使って変換する。
glibc における実装
MSVCRT と違い、 glibc は割と標準規格に沿っているのだが、 fopen に ccs 指定の独自仕様があるため、特別に取り上げる価値がある。
text stream / binary stream
知っての通り、 Linux だとこれらの間に違いはない。
byte-oriented stream / wide-oriented stream
fwide 関数で、orientation が定まっていないストリームの orientation を与えることができる。既に orientation が定まったストリームの orientation を変えることはできない。
wide-oriented stream に byte I/O function を呼ぶと失敗する。byte-oriented stream に wide character I/O function を呼んでも失敗する。

text / binary の区別がないので、割と単純な図となった。fopen 時に ,ccs=encoding を指定できるのが独自要素である。
fopen の ccs 指定
fopen の mode 引数に、 ,ccs=encoding という感じで文字コードを指定することができる。MSVCRT の類似機能とは違い、カンマと ccs の間にスペースを入れることはできない。
ストリームは開いた時点で wide-oriented stream となる。つまり、ccs を指定して開いたストリームに対して fprintf 等の byte I/O function を呼ぶことはできない。
調べた感じでは、この機能の初出は glibc 2.2 (2000年11月9日リリース)で、ワイド文字の標準入出力が実装されたのと同じタイミングである。【glibc 2.2 のアナウンス】
BSD libc における実装
UNIX 系の libc の実装として、 glibc の他に BSD libc の動作も調べた。この記事の実行結果は全て macOS で動作確認している。
ワイド文字と Unicode
BSD libc では wchar_t が表す文字はロケールに依存する。
ロケールの文字コードが ISO 8859-* の場合は、バイト値がそのまま wchar_t に収められるようである。つまり、 ISO 8859-1 以外を使う場合は wchar_t に収められる値は一般には Unicode のコードポイントとは異なる。
ロケールが UTF-8 な場合は、 wchar_t に収められる値は Unicode のコードポイントである。
text stream / binary stream
これらの間に違いはない。
byte-oriented stream / wide-oriented stream
fwide 関数で、orientation が定まっていないストリームの orientation を与えることができる。既に orientation が定まったストリームの orientation を変えることはできない。
しかし、ストリームの orientation によって何かが変わるというわけではなさそうだ。
どういうことかというと、wide-oriented stream に byte I/O function を呼ぶと成功して、バイト列がそのまま書き出される。byte-oriented stream に wide character I/O function を呼ぶと、ロケールに従ってワイド文字がマルチバイト文字に変換される。
図で表すと、こうなる:

fopen の ccs 指定
そんなものはない。単に無視される。
ロケール指定版の関数 (*_l)
基本的に、 setlocale で指定したロケールはプログラム全体または実行中のスレッド全体に影響を及ぼし、ロケール依存の関数はそのロケールを使う。しかし、 BSD libc にはロケールを明示的に指定できる関数が用意されている。通常のロケール依存の関数名の後に、 _l という接尾辞をつけたものが、ロケールを指定できる関数である。(例:fputws に対しては fputws_l)
以下では、検証に使ったコードと、実行例を見ていく。
例1:ワイド文字出力
fputws でワイド文字を出力する。その後、同じストリームに対して fputs を呼び出してみる。
glibc (Linux) での実行結果
“C” ロケールの場合
$ gcc -o test1 -Wall test1.c $ ./test1 LC_CTYPE = C LC_ALL = C orientation is not set. [0] fputws successful. [1] fputws successful. [1] fputws successful. [1] orientation is wide. [1] fputs failed. [-1] $ hexdump -C out.txt 00000000 43 61 66 3f 20 61 75 20 6c 61 69 74 0a 3f 0a 3f |Caf? au lait.?.?| 00000010 0a |.| 00000011
orientation に関しては、 fopen の直後は未設定 (0) だったものが、 fputws の呼び出しによって wide (正の値)に変化したのがわかる。
一旦 orientation が wide となった後は、byte I/O function である fputs の呼び出しは失敗している。
出力に関しては、非7ビット文字が “?” に化けている。この時、 fputws 関数はエラーを返していない。
“fr_FR.ISO-8859-1” ロケールの場合
事前にシステムに “fr_FR.ISO-8859-1” ロケールをインストールしておく必要がある。
$ ./test1 fr_FR.ISO-8859-1 LC_CTYPE = fr_FR.ISO-8859-1 LC_ALL = LC_CTYPE=fr_FR.ISO-8859-1;LC_NUMERIC=C;LC_TIME=C;LC_COLLATE=C;LC_MONETARY=C;LC_MESSAGES=C;LC_PAPER=C;LC_NAME=C;LC_ADDRESS=C;LC_TELEPHONE=C;LC_MEASUREMENT=C;LC_IDENTIFICATION=C orientation is not set. [0] fputws successful. [1] fputws successful. [1] fputws successful. [1] orientation is wide. [1] fputs failed. [-1] $ hexdump -C out.txt 00000000 43 61 66 e9 20 61 75 20 6c 61 69 74 0a 3f 0a 3f |Caf. au lait.?.?| 00000010 0a |.| 00000011
“é” の文字が 0xe9 として、つまり ISO-8859-1 で書き出されている。他の、 ISO-8859-1 にない文字は、 “?” に化けている。
setlocale 関数に空文字列を与えた場合は、環境変数等のシステム依存な方法でロケールを取得する。下の実行例では、 LANG 環境変数によってロケールを与えている。
$ LANG=fr_FR.ISO-8859-1 ./test1 "" LC_CTYPE = fr_FR.ISO-8859-1 LC_ALL = LC_CTYPE=fr_FR.ISO-8859-1;LC_NUMERIC=C;LC_TIME=C;LC_COLLATE=C;LC_MONETARY=C;LC_MESSAGES=C;LC_PAPER=C;LC_NAME=C;LC_ADDRESS=C;LC_TELEPHONE=C;LC_MEASUREMENT=C;LC_IDENTIFICATION=C orientation is not set. [0] fputws successful. [1] fputws successful. [1] fputws successful. [1] orientation is wide. [1] fputs failed. [-1]
“el_GR.ISO-8859-7” (ギリシャ語)ロケールの場合
ISO-8859-1 以外の8ビットなロケールも試しておく。事前にシステムに “el_GR.ISO-8859-7” ロケールをインストールしておく必要がある。
$ ./test1 el_GR.ISO-8859-7 LC_CTYPE = el_GR.ISO-8859-7 LC_ALL = LC_CTYPE=el_GR.ISO-8859-7;LC_NUMERIC=C;LC_TIME=C;LC_COLLATE=C;LC_MONETARY=C;LC_MESSAGES=C;LC_PAPER=C;LC_NAME=C;LC_ADDRESS=C;LC_TELEPHONE=C;LC_MEASUREMENT=C;LC_IDENTIFICATION=C orientation is not set. [0] fputws successful. [1] fputws successful. [1] fputws successful. [1] orientation is wide. [1] fputs failed. [-1] $ hexdump -C out.txt 00000000 43 61 66 65 20 61 75 20 6c 61 69 74 0a e6 0a 3f |Cafe au lait...?| 00000010 0a |.| 00000011
“é” はアクサンなしの “e” に化けている。ギリシャ文字 “ζ” は ISO 8859-7 における値である 0xe6 として出力されている。日本語の文字は “?” に化けた。
“ja_JP.UTF-8” ロケールの場合
$ ./test1 ja_JP.UTF-8 LC_CTYPE = ja_JP.UTF-8 LC_ALL = LC_CTYPE=ja_JP.UTF-8;LC_NUMERIC=C;LC_TIME=C;LC_COLLATE=C;LC_MONETARY=C;LC_MESSAGES=C;LC_PAPER=C;LC_NAME=C;LC_ADDRESS=C;LC_TELEPHONE=C;LC_MEASUREMENT=C;LC_IDENTIFICATION=C orientation is not set. [0] fputws successful. [1] fputws successful. [1] fputws successful. [1] orientation is wide. [1] fputs failed. [-1] $ hexdump -C out.txt 00000000 43 61 66 c3 a9 20 61 75 20 6c 61 69 74 0a ce b6 |Caf.. au lait...| 00000010 0a e3 81 82 0a |.....| 00000015
UTF-8 で書き出されている。
BSD libc (macOS) での実行結果
“C” ロケールの場合
$ clang -o test1 -Wall test1.c $ ./test1 LC_CTYPE = C LC_ALL = C orientation is not set. [0] fputws successful. [0] fputws failed. [-1] fputws failed. [-1] orientation is wide. [1] fputs successful. [13] $ hexdump -C out.txt 00000000 43 61 66 e9 20 61 75 20 6c 61 69 74 0a 43 61 66 |Caf. au lait.Caf| 00000010 e9 20 61 75 20 6c 61 69 74 0a |. au lait.| 0000001a
8ビット文字はそのまま出力されているが、8ビットに収まらない文字列を出力しようとした fputws 関数の呼び出しが失敗している。
また、 orientation が wide にも関わらず fputs の呼び出しに成功している。
“fr_FR.ISO8859-1” ロケールの場合
“C” ロケールの場合と同様である。
$ ./test1 "fr_FR.ISO8859-1" LC_CTYPE = fr_FR.ISO8859-1 LC_ALL = C/fr_FR.ISO8859-1/C/C/C/C orientation is not set. [0] fputws successful. [0] fputws failed. [-1] fputws failed. [-1] orientation is wide. [1] fputs successful. [13] $ hexdump -C out.txt 00000000 43 61 66 e9 20 61 75 20 6c 61 69 74 0a 43 61 66 |Caf. au lait.Caf| 00000010 e9 20 61 75 20 6c 61 69 74 0a |. au lait.| 0000001a
“el_GR.ISO8859-7” ロケールの場合
“C” ロケールの場合と同様である。BSD では wchar_t の値の解釈がロケール依存であることが分かる。
$ ./test1 "el_GR.ISO8859-7" LC_CTYPE = el_GR.ISO8859-7 LC_ALL = C/el_GR.ISO8859-7/C/C/C/C orientation is not set. [0] fputws successful. [0] fputws failed. [-1] fputws failed. [-1] orientation is wide. [1] fputs successful. [13] $ hexdump -C out.txt 00000000 43 61 66 e9 20 61 75 20 6c 61 69 74 0a 43 61 66 |Caf. au lait.Caf| 00000010 e9 20 61 75 20 6c 61 69 74 0a |. au lait.| 0000001a
“ja_JP.UTF-8” ロケールの場合
信頼と安定の UTF-8 である。glibc との違いは、 fputs の呼び出しが成功してバイト列がそのまま書き出されていることである。
$ ./test1 "ja_JP.UTF-8" LC_CTYPE = ja_JP.UTF-8 LC_ALL = C/ja_JP.UTF-8/C/C/C/C orientation is not set. [0] fputws successful. [0] fputws successful. [0] fputws successful. [0] orientation is wide. [1] fputs successful. [13] $ hexdump -C out.txt 00000000 43 61 66 c3 a9 20 61 75 20 6c 61 69 74 0a ce b6 |Caf.. au lait...| 00000010 0a e3 81 82 0a 43 61 66 e9 20 61 75 20 6c 61 69 |.....Caf. au lai| 00000020 74 0a |t.| 00000022
例2:fopen への ccs 指定
fopen に ,ccs=UTF-8 を指定してみる。
glibc での実行結果
$ gcc -o test2 -Wall test2.c $ ./test2 LC_CTYPE = C LC_ALL = C orientation is wide. [1] fputws successful. [1] fputws successful. [1] fputws successful. [1] orientation is wide. [1] fputs failed. [-1] $ hexdump -C out.txt 00000000 43 61 66 c3 a9 20 61 75 20 6c 61 69 74 0a ce b6 |Caf.. au lait...| 00000010 0a e3 81 82 0a |.....| 00000015
例1とは違い、fopen の直後から wide-oriented となっている。
,ccs=UTF-8 を指定しなかった場合は “é” “ζ” “あ” の出力結果はロケール依存だったが、今回はロケールに関わらず UTF-8 で書き込まれている。
fputs の呼び出しはやはり失敗する。
読者への演習:fopen の第2引数を "w, ccs=UTF-8" (カンマと “ccs” との間に空白を入れる)に変えた場合に、実行結果が例1(ccs を指定しなかった場合)と同一になることを確かめよ。(つまり、カンマと ccs の間に空白を入れてはいけない)
読者への演習:fopen の第2引数を "w,ccs=UNICODE" または "w,ccs=UTF-16LE" とした場合に、書き出されたファイルが BOM なしの UTF-16LE となることを確かめよ。(リトルエンディアンの場合。ビッグエンディアンの場合は変わるかも?)
BSD libc での実行結果
,ccs= 指定は解釈されず、ただ無視されるだけである。よって、実行結果は例1と同じである。
例2b:バイナリモードと ccs 指定
test2.c における fopen の第2引数を "wb,ccs=UTF-8" に変えたものを test2b.c とする。
glibc での実行結果
そもそもテキストモードとバイナリモードの区別がないので、実行結果は例2と同じになる。
BSD libc での実行結果
テキストモードとバイナリモードの区別がないので(ry
例3:ccs 指定と fwrite
,ccs=UTF-8 を指定して開いたストリームに対して、 fwrite を呼び出すとどうなるか。
glibc での実行結果
$ gcc -o test3 -Wall test3.c $ ./test3 fwrite failed. [0]
wide-oriented なストリームに対する byte I/O function の呼び出しなので、失敗する。
BSD libc での実行結果
,ccs= 指定が認識されないので、普通に wchar_t[] の中身が出力される。仮にストリームが wide-oriented だったとしても同じ結果となる。
$ clang -o test3 -Wall test3.c $ ./test3 fwrite successful. [13] $ hexdump -C out.txt 00000000 43 00 00 00 61 00 00 00 66 00 00 00 e9 00 00 00 |C...a...f.......| 00000010 20 00 00 00 61 00 00 00 75 00 00 00 20 00 00 00 | ...a...u... ...| 00000020 6c 00 00 00 61 00 00 00 69 00 00 00 74 00 00 00 |l...a...i...t...| 00000030 0a 00 00 00 |....| 00000034
例4:ファイルからの読み込み
glibc での実行結果
テストプログラム中では全て ccs を指定しているので、ロケールには依存しない。
$ gcc -o test4 -Wall test4.c $ ./test4 LC_CTYPE = C LC_ALL = C Read from UTF-8-encoded file (with ccs=UTF-8): 00e9 03b6 3042 1f376 000d 000a Read from UTF-8-encoded file (with ccs=UNICODE): a9c3 b6ce 81e3 f082 8d9f 0db6 Read from UTF-8-encoded file (with ccs=UTF-16): a9c3 b6ce 81e3 f082 8d9f 0db6 Read from UTF-8-encoded file (with ccs=UTF-16LE): a9c3 b6ce 81e3 f082 8d9f 0db6 Read from UTF-8 (with BOM)-encoded file (with ccs=UTF-8): feff 00e9 03b6 3042 1f376 000d 000a Read from UTF-8 (with BOM)-encoded file (with ccs=UNICODE): bbef c3bf cea9 e3b6 8281 9ff0 b68d 0a0d Read from UTF-8 (with BOM)-encoded file (with ccs=UTF-16): bbef c3bf cea9 e3b6 8281 9ff0 b68d 0a0d Read from UTF-8 (with BOM)-encoded file (with ccs=UTF-16LE): bbef c3bf cea9 e3b6 8281 9ff0 b68d 0a0d Reading UTF-16LE (with BOM)-encoded file with ccs=UTF-8 failed. Reading UTF-16LE (with BOM)-encoded file with ccs=UNICODE failed. Read from UTF-16LE (with BOM)-encoded file (with ccs=UTF-16): 00e9 03b6 3042 1f376 000d 000a Read from UTF-16LE (with BOM)-encoded file (with ccs=UTF-16LE): feff 00e9 03b6 3042 1f376 000d 000a Reading UTF-16BE (with BOM)-encoded file with ccs=UTF-8 failed. Reading UTF-16BE (with BOM)-encoded file with ccs=UNICODE failed. Read from UTF-16BE (with BOM)-encoded file (with ccs=UTF-16): 00e9 03b6 3042 1f376 000d 000a Read from UTF-16BE (with BOM)-encoded file (with ccs=UTF-16LE): fffe e900 b603 4230 3cd8 76df 0d00 0a00 fread on file handle with ccs=UTF-8 failed. fread on file handle with ccs=UTF-8 failed.
BOM 付き UTF-16 のファイルを ccs=UTF-16 で読み込むと、正しく読み取られる。一方、BOM 付き UTF-8 のファイルを ccs=UTF-16 で読み込もうとしても UTF-8 のデコードはされない。
ccs=UNICODE は ccs=UTF-16 と似ているが、 BMP 外の文字(サロゲートペアを使う文字)を処理できない。
ccs=UTF-8, ccs=UTF-16LE, ccs=UTF-16BE を指定すると、ファイルをその文字コードで解釈する。BOM があったとしても無視される(文字コードが合致していれば U+FEFF として読まれる)。
文字コードの変換には iconv を使っていると思われるので、これ以上のことは iconv のマニュアルを参照するなりされたい。
ちなみに、 fread は byte I/O function なので、失敗する。
BSD libc での実行結果
BSD libc では ccs 指定は無視されるので、実行結果はロケール依存となる。
“C” ロケールの場合
$ clang -o test4 -Wall test4.c $ ./test4 LC_CTYPE = C LC_ALL = C Read from UTF-8-encoded file (with ccs=UTF-8): 00c3 00a9 00ce 00b6 00e3 0081 0082 00f0 009f Read from UTF-8-encoded file (with ccs=UNICODE): 00c3 00a9 00ce 00b6 00e3 0081 0082 00f0 009f Read from UTF-8-encoded file (with ccs=UTF-16): 00c3 00a9 00ce 00b6 00e3 0081 0082 00f0 009f Read from UTF-8-encoded file (with ccs=UTF-16LE): 00c3 00a9 00ce 00b6 00e3 0081 0082 00f0 009f Read from UTF-8 (with BOM)-encoded file (with ccs=UTF-8): 00ef 00bb 00bf 00c3 00a9 00ce 00b6 00e3 0081 Read from UTF-8 (with BOM)-encoded file (with ccs=UNICODE): 00ef 00bb 00bf 00c3 00a9 00ce 00b6 00e3 0081 Read from UTF-8 (with BOM)-encoded file (with ccs=UTF-16): 00ef 00bb 00bf 00c3 00a9 00ce 00b6 00e3 0081 Read from UTF-8 (with BOM)-encoded file (with ccs=UTF-16LE): 00ef 00bb 00bf 00c3 00a9 00ce 00b6 00e3 0081 Read from UTF-16LE (with BOM)-encoded file (with ccs=UTF-8): 00ff 00fe 00e9 Read from UTF-16LE (with BOM)-encoded file (with ccs=UNICODE): 00ff 00fe 00e9 Read from UTF-16LE (with BOM)-encoded file (with ccs=UTF-16): 00ff 00fe 00e9 Read from UTF-16LE (with BOM)-encoded file (with ccs=UTF-16LE): 00ff 00fe 00e9 Read from UTF-16BE (with BOM)-encoded file (with ccs=UTF-8): 00fe 00ff Read from UTF-16BE (with BOM)-encoded file (with ccs=UNICODE): 00fe 00ff Read from UTF-16BE (with BOM)-encoded file (with ccs=UTF-16): 00fe 00ff Read from UTF-16BE (with BOM)-encoded file (with ccs=UTF-16LE): 00fe 00ff fread on file handle with ccs=UTF-8 failed. Read from UTF-8-encoded file with fread: b6cea9c3 f08281e3 db68d9f Read from UTF-8-encoded file with fread: c3 a9 ce b6 e3 81 82 f0 9f 8d b6 0d
fgetws はファイルから読み取った1バイトの値が wchar_t の 0 から 255 の値にマップしている。
fread は、ファイルの中身を普通にバイナリ列として読み取っている。
UTF-8 なロケールの場合
$ ./test4 ja_JP.UTF-8 LC_CTYPE = ja_JP.UTF-8 LC_ALL = C/ja_JP.UTF-8/C/C/C/C Read from UTF-8-encoded file (with ccs=UTF-8): 00e9 03b6 3042 1f376 000d 000a Read from UTF-8-encoded file (with ccs=UNICODE): 00e9 03b6 3042 1f376 000d 000a Read from UTF-8-encoded file (with ccs=UTF-16): 00e9 03b6 3042 1f376 000d 000a Read from UTF-8-encoded file (with ccs=UTF-16LE): 00e9 03b6 3042 1f376 000d 000a Read from UTF-8 (with BOM)-encoded file (with ccs=UTF-8): feff 00e9 03b6 3042 1f376 000d 000a Read from UTF-8 (with BOM)-encoded file (with ccs=UNICODE): feff 00e9 03b6 3042 1f376 000d 000a Read from UTF-8 (with BOM)-encoded file (with ccs=UTF-16): feff 00e9 03b6 3042 1f376 000d 000a Read from UTF-8 (with BOM)-encoded file (with ccs=UTF-16LE): feff 00e9 03b6 3042 1f376 000d 000a Reading UTF-16LE (with BOM)-encoded file with ccs=UTF-8 failed. Reading UTF-16LE (with BOM)-encoded file with ccs=UNICODE failed. Reading UTF-16LE (with BOM)-encoded file with ccs=UTF-16 failed. Reading UTF-16LE (with BOM)-encoded file with ccs=UTF-16LE failed. Reading UTF-16BE (with BOM)-encoded file with ccs=UTF-8 failed. Reading UTF-16BE (with BOM)-encoded file with ccs=UNICODE failed. Reading UTF-16BE (with BOM)-encoded file with ccs=UTF-16 failed. Reading UTF-16BE (with BOM)-encoded file with ccs=UTF-16LE failed. fread on file handle with ccs=UTF-8 failed. Read from UTF-8-encoded file with fread: b6cea9c3 f08281e3 db68d9f Read from UTF-8-encoded file with fread: c3 a9 ce b6 e3 81 82 f0 9f 8d b6 0d
fgetws はファイルの中身を UTF-8 として解釈しようとする。UTF-16 の BOM は UTF-8 では不正なバイト列なので、 fgetws の呼び出しが失敗している。
ピンバック: C言語のワイド文字入出力 — MSVCRTの場合 | 雑記帳